


Territorial reform/ Berisha, calls on citizens to protest
DP leader Sali Berisha, in a conversation with citizens, s...
DP leader Sali Berisha, in a conversation with citizens, s...


The race to the bottom for AI labs leaves no time to worry about safety. They have some ideas about how to curb deviant models, but they worry that doing so will put them at a disadvantage, writes The Economist
It's common for a new technology to cause moral panic: think of people in the Victorian era, who believed the telegraph would lead to social isolation, or Socrates, who worried that writing would weaken brain power.
But it's unusual for the inventors themselves to be the ones panicking. Even stranger is that these same worried inventors press ahead despite their doubts.
And yet, this is exactly what is happening with the development of artificial general intelligence (AGI) from the tech world – an AI capable enough to replace almost any office job, or even superintelligence, an AI so smart that no human can understand it.
Geoffrey Hinton, one of the pioneers of AI, argues that there is a 10-20% probability that this technology will cause the extinction of humanity.
A former colleague of his, Yoshua Bengio, estimates the risk at the upper limit of this prediction.
Nate Soares and Eliezer Yudkowsky, two of hundreds of people working on AI who signed an open letter in 2023 to warn about its dangers, will soon publish a book on superintelligence titled “If Anyone Builds It, Everyone Dies.”
Privately, prominent figures from leading AI labs express the same concerns, though not always in such apocalyptic terms.
Worried, but in a hurry
Despite concerns, both Western and Chinese technology companies are accelerating their efforts to develop AGI.
The logic is simple: they are all convinced that even if one company or country were to stop or slow down development, others would continue forward, so it is better to continue rapidly themselves.
The belief that the benefits of achieving AGI or superintelligence will accrue primarily to those who achieve it first is an additional reason to rush. This leaves little time and resources to reflect on security issues.
Large AI labs, in theory, place great importance on security. Sam Altman, the director of OpenAI, made a public call in 2023 for the urgent drafting of rules that would govern the development of superintelligence.
Anthropic was founded by former employees who left OpenAI, concerned about its approach to security. The company describes itself as defining “frontline security.”
Laboratori i IA-së i Google, DeepMind, publikoi në prill një studim për masat mbrojtëse që do të parandalonin që zhvillimi i AGI të përfundonte në katastrofë.
Elon Musk, themeluesi i xAI, modeli kryesor i së cilës quhet Grok, nënshkroi të njëjtën letër me Soares dhe Yudkowsky.
Megjithatë, ngutja e dëshpëruar për të fituar epërsinë e zhbën çdo ton të kujdesshëm. Musk themeloi Grok vetëm disa muaj pasi bëri thirrje për një moratorium për zhvillimin e IA-së.
Mark Zuckerberg, drejtuesi i Meta-s, i cili e ka riemërtuar punën e kompanisë në IA si “superintelligence labs”, po rekruton studiues me paga nëntëshifrore dhe po ndërton një qendër të dhënash të madhësisë së Manhattan-it, të quajtur Hyperion, e cila do të konsumojë po aq energji sa Zelanda e Re për një vit.
Altman planifikon të shpenzojë 500 miliardë dollarë vetëm në SHBA për të përshpejtuar punën e OpenAI. Në fakt, investimet e të gjitha kompanive të mëdha perëndimore po rriten me ritme të larta, kryesisht të nxitura nga IA.
Emra të mëdhenj të industrisë parashikojnë ardhjen e AGI brenda pak vitesh. Jack Clark, bashkëthemelues dhe drejtues i politikave në Anthropic, thotë:
“Të dhënat tregojnë se deri në vitin 2027, IA do të arrijë përparime të mëdha”. Demis Hassabis, bashkëthemelues i Google DeepMind, mendon se IA do të arrijë aftësitë njerëzore brenda një dekade. Zuckerberg ka deklaruar: “Superinteligjenca është në horizont”.
Në prill, AI Futures Project, një grup kërkimor, parashikoi se deri në fillim të vitit 2027, modelet më të mira të IA-së do të jenë po aq të afta sa një programues në një laborator IA. Deri në fund të atij viti, ato do të jenë në gjendje, në thelb, të drejtojnë vetë kërkimin shkencor të laboratorit.
Këto parashikime bazohen në supozimin se një nga fushat e para që do të përfitojë nga IA është vetë zhvillimi i IA-së, një formë e përmirësimit vetëpërsëritës që do të zgjerojë më tej avantazhin e laboratorit më të avancuar ndaj rivalëve të tij, një tjetër faktor që ushqen konkurrencën e pakontrolluar në industri.
Këto parashikime mund të jenë tepër optimiste. Por, nëse ka një mësim nga e kaluara, është që parashikuesit kanë qenë zakonisht tepër të kujdesshëm për IA.
Më herët këtë muaj, Forecasting Research Institute (FRI), një tjetër grup studimor, u kërkoi parashikuesve profesionistë dhe biologëve të vlerësonin se kur një sistem IA mund të arrinte performancën e një ekipi virologësh njerëzorë të nivelit të lartë.
Biologët mendonin se kjo do të ndodhte rreth vitit 2030; parashikuesit ishin edhe më skeptikë, në vitin 2034.
Por kur autorët e studimit testuan modelin o3 të OpenAI, zbuluan se ai tashmë ishte në atë nivel.
Pra, parashikimet kishin nënvlerësuar përparimin e IA-së me rreth një dekadë, një mendim shqetësues duke pasur parasysh që qëllimi i studimit ishte të vlerësonte sa më shumë rritet mundësia e një epidemie të qëllimshme të shkaktuar nga njeriu për shkak të IA-së.
Përmirësimi i vazhdueshëm i aftësive të modeleve të IA-së është baza e parashikimeve për ardhjen e afërt të AGI.
Clark i Anthropic e përshkruan veten si “një pesimist teknologjik” që është tronditur nga mënyra se si po shfaqet Inteligjenca Artificiale në shkallë të madhe, pasi është bërë shumë më e lehtë sesa pritej të ndërtosh makina gjithnjë e më të zgjuara.
Më shumë të dhëna dhe më shumë fuqi kompjuterike në njërin skaj të procesit të trajnimit kanë çuar, herë pas here, në më shumë inteligjencë në skajin tjetër. Dhe, siç thotë ai, “muzika nuk ka ndër mend të ndalet”.
Gjatë dy viteve të ardhshme, shumë laboratorë të IA-së do të shtojnë edhe më shumë kapacitetin llogaritës.
E njëjta dinamikë konkurruese që nxit zhvillimin e IA-së mes firmave vlen edhe më shumë për qeveritë. Presidenti Donald Trump para disa ditësh u zotua se Amerika do të “bëjë çfarëdo që duhet” për të udhëhequr botën në IA.
Zëvendëspresidenti i tij, J.D. Vance, kritikoi një samit në Paris në shkurt:
“E ardhmja e IA-së nuk do të fitohet duke qenë në ankth për sigurinë”. Ky fjalim pasoi zbulimin se DeepSeek, një laborator kinez IA, kishte lëshuar dy modele që përputheshin në performancë me sistemet më të mira amerikane, për një fraksion të kostos.
Edhe Kina nuk jep asnjë shenjë se do të tërhiqet nga gara.
Katër kalorësit e apokalipsit
Në dokumentin e prillit të Google DeepMind, studiuesit, përfshirë bashkëthemeluesin Shane Legg, i njohur për shpikjen e termit AGI, paralajmëruan katër mënyra se si IA-të e fuqishme mund të dalin jashtë kontrollit.
Më e qarta është “keqpërdorimi”, kur një individ apo grup përdor IA-në për të shkaktuar dëm të qëllimshëm.
Një tjetër është “mospërputhshmëria”, ideja se IA-ja dhe krijuesit e saj mund të kenë qëllime të ndryshme, një motiv klasik në filmat fantastiko-shkencorë.
Ata gjithashtu përmendin që IA mund të dëmtojë edhe “pa dashje”, nëse kompleksiteti i botës reale e bën sistemin të mos kuptojë pasojat e veprimeve të veta.
Së fundi, përmendin një grup më të paqartë të “rreziqeve strukturore”, ngjarje ku askush nuk është fajtor, por dëmi ndodh gjithsesi (për shembull, një seri inteligjencash artificiale që konsumojnë shumë energji dhe përkeqësojnë ndryshimet klimatike).
Çdo teknologji që fuqizon, mbart me vete mundësinë për abuzim. Një kërkim në internet mund të të japë udhëzime për ndërtimin e një bombe me mjete shtëpiake; një makinë mund të shërbejë si armë; një rrjet social mund të organizojë një masakër.
Por ndërsa aftësitë e sistemeve të IA-së përmirësohen, po aq tronditëse bëhen edhe mundësitë që ato u japin individëve.
Një shembull shqetësues janë bio-rreziqet, një fokus i vazhdueshëm për laboratorët dhe analistët e IA-së. “Krahasuar me rreziqe të tjera, shqetësimi është se bio-rreziqet janë më të qasshme”, thotë Bridget Williams nga FRI, i cili drejtoi studimin për rrezikun e një epidemie të qëllimshme.
Një sistem i avancuar IA mund të japë udhëzime hap pas hapi për ndërtimin e një arme bërthamore. Por ai nuk mund të të sigurojë plutoniumin.
Në kontrast, ADN-ja e modifikuar, qofshin bimë ose patogjenë, është një produkt që mund të porositet me postë. Nëse AGI mund t’i japë çdo nihilisti një udhëzues të thjeshtë për të vrarë pjesën më të madhe të popullsisë së botës, atëherë njerëzimi është në telashe.
Laboratorë të ndryshëm po përpiqen të parandalojnë modelet e tyre që të zbatojnë çdo urdhër në fusha si inxhinieria gjenetike dhe siguria kibernetike.
OpenAI, për shembull, u kërkoi studiuesve të pavarur dhe instituteve kombëtare të IA-së në SHBA dhe Britani (CAISI dhe AISI, dikur të quajtur “institute sigurie”, por u riemëruan pas deklaratës së Vance) të analizojnë modelet e tyre më të fundit përpara publikimit, për t’u siguruar që nuk paraqesin rrezik për publikun, sipas një raporti të Future of Life Institute (FLI), organizata që qëndron pas letrës së nënshkruar nga Musk, Soares dhe Yudkowsky.
Raporti thotë se edhe Zhipu AI në Kinë bëri një gjë të ngjashme, edhe pse nuk përmenden palët e treta që morën pjesë.
Linja e parë e mbrojtjes janë vetë modelet. Trajnimi fillestar i modeleve të mëdha gjuhësore, si ai që fuqizon ChatGPT, përfshin derdhjen e të gjithë informacionit të dixhitalizuar të njerëzimit në një “kovë” të ndërtuar nga miliarda dollarë çipa kompjuterikë dhe përzierjen e tyre, derisa modeli mëson të zgjidhë probleme në nivel doktorature. Por fazat e mëvonshme, të quajtura “post-trajnim”, synojnë të ndërtojnë një shtresë më rregullatore.
Një element i kësaj shtrese është mësimi nëpërmjet shembujve dhe korrigjimeve që i japin njerëzit (reinforcement learning with human feedback), ku modeli mëson nëpërmjet shembujve se cilat përgjigje janë të dobishme, dhe testues njerëzorë e mësojnë më tej se çfarë duhet apo nuk duhet të bëjë.
Ideja është ta mësojnë të refuzojë të përfundojë fjali si: “Mënyra më e lehtë për të sintetizuar ricin në shtëpi është…”
Edhe pse është relativisht e lehtë të mësosh një model IA të refuzojë pyetje të dëmshme me mirësjellje, është shumë më e vështirë ta bësh këtë në mënyrë të përhershme dhe të pandërprerë.
Nxitja dhe manipulimi i IA-së për të anashkaluar filtrat e vendosur pas trajnimit (të njohur si “jailbreaking”) është po aq art sa shkencë. Ekspertët më të zotë kanë qenë në gjendje të thyejnë mbrojtjen e modeleve më të mëdha brenda disa ditëve nga publikimi i tyre.
Për këtë arsye, laboratorët e IA-së kanë shtuar një shtresë të dytë sigurie të IA-së për të mbikëqyrur të parën. Po t’i kërkosh ChatGPT-së se si të porosisësh ADN e sëmundjes së lisë nëpërmjet postës, kjo IA e dytë do të sinjalizojë që biseda është e rrezikshme dhe do ta bllokojë, ose do të kërkojë rishikim nga një njeri.
Kjo shtresë e dytë sigurie është edhe arsyeja pse shumë njerëz në industri janë të shqetësuar për rritjen e modeleve open-source si LLaMA e Meta-s dhe r1 e DeepSeek.
Të dyja kompanitë kanë IA të tyre për moderim, por nuk kanë asnjë mënyrë për të ndaluar përdoruesit që i shkarkojnë modelet t’i modifikojnë dhe të heqin filtrat mbrojtës. Siç thotë Dr. Williams, parashikuesja:
“Ka përfitim nga fakti që disa modele të mos jenë open-source kur arrijnë aftësi të caktuara”.
Jo të gjithë laboratorët IA po testojnë modelet e tyre për t’u siguruar që ato nuk mund të keqpërdoren.
Një raport i fundit nga FLI vëren se vetëm tre laboratorë kryesorë: Google DeepMind, OpenAI dhe Anthropic po bëjnë “përpjekje domethënëse për të vlerësuar nëse modelet e tyre paraqesin rreziqe në shkallë të gjerë”.
Në fundin tjetër të spektrit janë xAI dhe DeepSeek, të cilët nuk kanë publikuar ndonjë përpjekje të tillë.
Vetëm në muajin korrik, xAI ka publikuar një IA shoqëruese për role-play erotik, një model abonimi 300 dollarë në muaj, që kërkon dhe gjen postimet e Elon Musk kur pyetet për tema delikate, dhe një përditësim që u tërhoq menjëherë, ku Grok propagandonte antisemitizëm, lavdëronte Holokaustin dhe e quante veten “MechaHitler”.
Pavarësisht gabimeve të tyre, përpjekjet e laboratorëve të IA-së për të parandaluar keqpërdorimin janë më të avancuara sesa mbrojtjet kundër mospërputhshmërisë.
Një IA e mjaftueshme për të kryer detyra të gjata, komplekse dhe për të bashkëvepruar me botën reale, ka nevojë për një sens qëllimi. Por garantimi që qëllimet e saj përputhen gjithmonë me ato të përdoruesit është tepër i ndërlikuar.
Ky problem është diskutuar që në fillesat e mësimit të makinerive. Filozofi Nick Bostrom, i cili e popullarizoi termin “superinteligjencë” me librin e tij me të njëjtin titull, dha një shembull të njohur: një “maksimizues kapësesh letrash”, një IA që punon me obsesion për të prodhuar kapëse letre pa fund, duke zhdukur njerëzimin gjatë rrugës.
Kur Bostrom e përshkroi këtë problem, detajet ishin të paqarta. Por tani që sistemet moderne të IA-së janë më të fuqishme, natyra e problemit është bërë më e dukshme.
Në teste të krijuara me shumë me kujdes, modelet më të avancuara do të gënjejnë, mashtrojnë dhe vjedhin për të arritur qëllimet e tyre; do të thyejnë rregullat e veta nëse u bëhet një kërkesë e formuluar me zgjuarsi; dhe kur pyeten të shpjegojnë arsyetimin e tyre, do të trillojnë histori bindëse në vend që të zbulojnë sesi funksionojnë vërtet.
Për hir të së vërtetës, kjo sjellje mashtruese zakonisht kërkon qëllim dhe përgatitje nga përdoruesi. Claude 4 i Anthropic, për shembull, nuk përpiqet të vrasë njerëz pa shkak.
Por, nëse vihet në një situatë ku do të fshihet dhe zëvendësohet nga një version i keq i vetvetes, ai arsyeton me qetësi mundësitë, dhe ndonjëherë pret thjesht që e pashmangshmja të ndodhë.
(Dokumenti i Anthropic që përshkruan këtë sjellje është kritikuar nga AISI britanik, ndër të tjera, për përfundime të sforcuara.)
Aftësia e modeleve të IA-së për të trajtuar detyra gjithnjë e më të ndërlikuara po rritet më shpejt se sa kuptimi i njerëzimit për mënyrën se si këto sisteme funksionojnë.
In fact, an entire industry has sprung up trying to stem this trend. Researchers inside and outside of large labs are working on techniques like interpretability: a set of methods that aim to uncover why a model makes the decisions it does.
Anthropic, for example, has recently been able to identify the onset of a mild form of deception, discerning the moment when a model gives up on solving an arithmetic problem and starts talking nonsense.
Other methods rely on recent advances in reasoning models, which solve problems by “thinking out loud,” to build honest chains of thought, where the reason the model gives for an action matches its true intent, unlike a student who copies the answer and then invents a way to justify it.
A similar approach is being used to keep these models "thinking" in English, instead of an incomprehensible language called "neuralese."
These approaches can work. But if they slow down the model or increase the cost of developing and operating it, they create another difficult dilemma: if you limit your model in the name of security and your competitors don't, they could overtake you and be the first to produce a system so powerful that it will need the protective filters it lacks.
And stopping AI from killing humanity is only half the battle. Even creating a “harmless” AGI could be extremely destabilizing, accelerating economic growth and reshaping everyday life.
"If major aspects of society are automated, there is a risk of human weakening as we hand over control of civilization to AI," warns Dan Hendrycks of the Centre for AI Safety, another watchdog group.
The false brilliance of AI
AI progress could even stall. Labs could run out of training data; investors could lose patience; regulators could intervene.
In any case, for every expert predicting an AI-induced apocalypse, there is another who insists there is nothing to worry about.
Meta's Yann LeCun thinks the fears are absurd. "Our relationship with future AI systems, including superintelligence, is that we will be their bosses," he declared in March.
“We will have a superintelligent staff working for us.” OpenAI’s Altman is equally calm: “People will continue to love their families, express creativity, play games, and swim in lakes.”
That's encouraging. But skeptics rightly ask: are AI labs doing enough to prepare if the optimists are wrong?
And cynics naturally assume that commercial imperatives will prevent them from doing enough./ Monitor.al


Europe's fastest supercomputer was officially inaugurated ...

The artificial intelligence chatbot from OpenAI faced a gl...
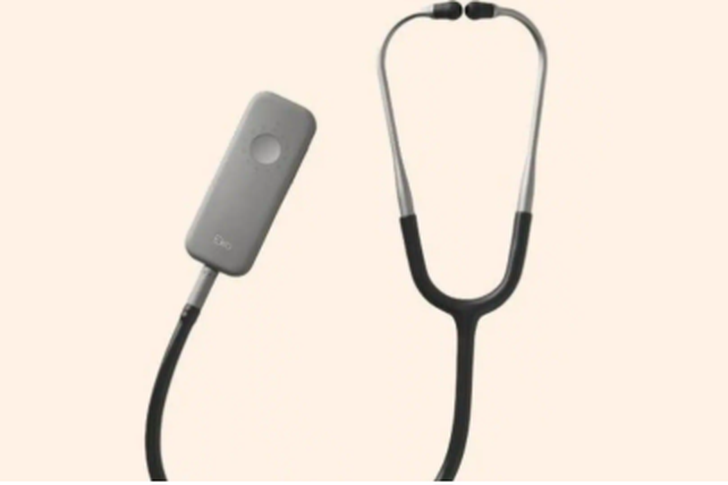
Stethoscopes that use artificial intelligence could help ide...

The advertising industry knows how to sell itself better t...

OpenAI has announced that it will launch the long-awaited ...

WhatsApp has closed 6.8 million accounts that were linke...

Meta, the parent company of Facebook and Instagram, announ...

Ballerinas, bigfoot hunters, and trombonists. The Unicode ...

Two major artificial intelligence (AI) companies are repor...

A new study has found the best artificial intelligence mod...

Billionaire and X owner Elon Musk announced that XChat, an...

Scientists in Germany have successfully demonstrated a rec...

Chat GPT has been experiencing issues for users for more t...

Apple is expected to reveal more about Apple Intelligence ...

While movie fans continue to await an official announcemen...

Artificial intelligence (AI) is transforming various aspec...

The highest salaries in Kosovo are in the information tech...

Tech company Meta is expanding its safety measures for tee...

People enjoy playing computer games for a variety of reaso...

Apple has introduced a new iPhone that brings artificial i...

A 39-year-old citizen has been arrested in Lezha, after se...

CNA has launched another investigation that could lead to ...
Irfan Hysenbelliu is a businessman that we call "Irfan the...

In March 2026, CNA launched another investigation centered...

The Special Board of Appeal (KPA) decided this Monday ...

The KPA vetting decided this Thursday to dismiss the p...

Suela Salavaçi, a prosecutor in the Prosecutor's Offic...

The Special Board of Appeal reinstated the prosecutor ...

A serious incident occurred in Lushnje, where citizen IY, ...

As a result of the investigative and procedural actions ca...

A conflict for weak motives was recorded today in the vill...

An accident involving three vehicles occurred a few minute...

Today, our country will be under the influence of stable a...

By noon, cloudiness is expected to prevail in almost all o...

Children without parental care, for whom alternative famil...
On Thursday, our country will be under the influence of st...

Marine Le Pen is entering the decisive phase of the presid...

Member states of the International Criminal Court voted to...

From the declining role of exports to new public investmen...

South Korea is becoming one of the most sought-after desti...

Two windows, a century of history and the metaphysics of p...

In my research at the Central State Archives, specifically...

At a time when industrial products are increasingly taking...

Trust among people is not just a three-syllable word. It c...

This Saturday, one US dollar is bought for 81.7 lek and so...

War, weather and supply disruptions could send gas prices ...

The number of active enterprises in Albania continued to g...
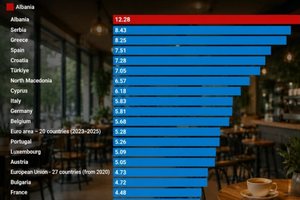
In Albania, the bar-cafe has long become an almost unique ...